本文共 2979 字,大约阅读时间需要 9 分钟。
[本文出自天外归云的博客园]
Python3下一些nose插件经过2to3的转换后失效了
Python的nose测试框架是通过python2编写的,通过pip3install的方式安装的nose和相关生成报表的插件,执行测试时会报错。原因多是因为涉及到的插件或相关代码是用python2编写的。我们通过python2自带的工具2to3.py文件就可以完成从python2到python3的自动转换。
拿nose_html_reporting插件的转换举例:
将2to3.py文件(Python27/Tools/Scripts路径下可以找到)复制粘贴到nose_html_reporting路径下,执行2to3的转换命令:
python 2to3.py -w __init__.py
执行命令后会在当前路径下自动生成一个__init__.py的备份(bk)文件,和一份已经自动转换成python3的__init__.py文件。
类似要做修改的还有在其他的nose相关的文件夹路径(nose、nose_html_reporting、nose_ittr):
分别cd到以上三个路径下,然后对其中的py文件分别执行2to3的转换命令。或者直接在上级目录对该目录的路径执行2to3的命令,这会让该目录下所有的py文件都完成2to3的转换。
之后就可以让一些nose的插件支持在python3下运行了。
2to3转换的同时也带来了坑
这个转换过程中我也发现了一个坑,2to3以后,原来的ittr_multiplier.py文件中dct.items()会被转成list(dct.items()),而python3中map的含义比较python2也发生了变化。我在执行需要ittr插件支持的测试时发现代码转换后功能并没有生效。经过我在网上查,发现python3中的items和python2中的iteritems方法是有区别的,包括map的定义也会发生变化等等。经我测试,将nose_ittr文件夹中的文件2to3以后,nose_ittr的功能是可以使用的,但是不能传列表值,如果ittr传参传入的是字符串值还好,如果传入的是含有多个字符串值的列表就会有问题,执行测试会报错,要自己再处理列表中的数据。
所以我决定避开插件2to3转换后出现的坑。
我的思路是做一个专门的工具类,用来读取存放在csv文件中的测试数据,联合nose_parameterized一起发挥与java测试框架TestNG中dataprovider类似的功能。
首先封装一个取测试数据的工具类叫“test_data_tool.py”,代码如下:
import csvclass T_data_reader(object): def __init__(self, file_path): setattr(self, 'file_content_lines', []) csv_reader = csv.reader(open(file_path, encoding='utf-8')) for row in csv_reader: self.file_content_lines.append(row) fields = self.file_content_lines[0] setattr(self, 't_data_count', len(self.file_content_lines)-1) # Traverse t data. for i in range(len(self.file_content_lines)-1): t_data = {} for j in range(len(fields)): t_data[fields[j]] = self.file_content_lines[i+1][j] setattr(self, 't_data_'+str(i+1), t_data) def get_t_data_count(self): return self.t_data_count def get_t_data(file_path): t_data_reader = T_data_reader(file_path) t_data_count = t_data_reader.get_t_data_count() t_data = [] for i in range(t_data_count): t_data.append(getattr(t_data_reader,"t_data_"+str(i+1))) return t_data 然后修改测试用例py文件模样如下:
# -*- coding: utf-8 -*-from nose.tools import *from test_data_tool import *from parameterized import parameterized@istestclass Test(): file_path = "QueryTradeInfoTester.csv" @parameterized.expand([ (file_path, 1), (file_path, 2), (file_path, 3), ]) def test_1(self, file_path, t_data_number): t_data = get_t_data(file_path) setattr(self, 't_data', t_data[t_data_number-1]) assert_equal(self.t_data['retCode'],"200")
以上就达到了与java中TestNG框架dataprovider所能达到的类似作用。
其中setattr方法将自身的测试数据分别指向测试数据文件的第一、二、三行。
测试
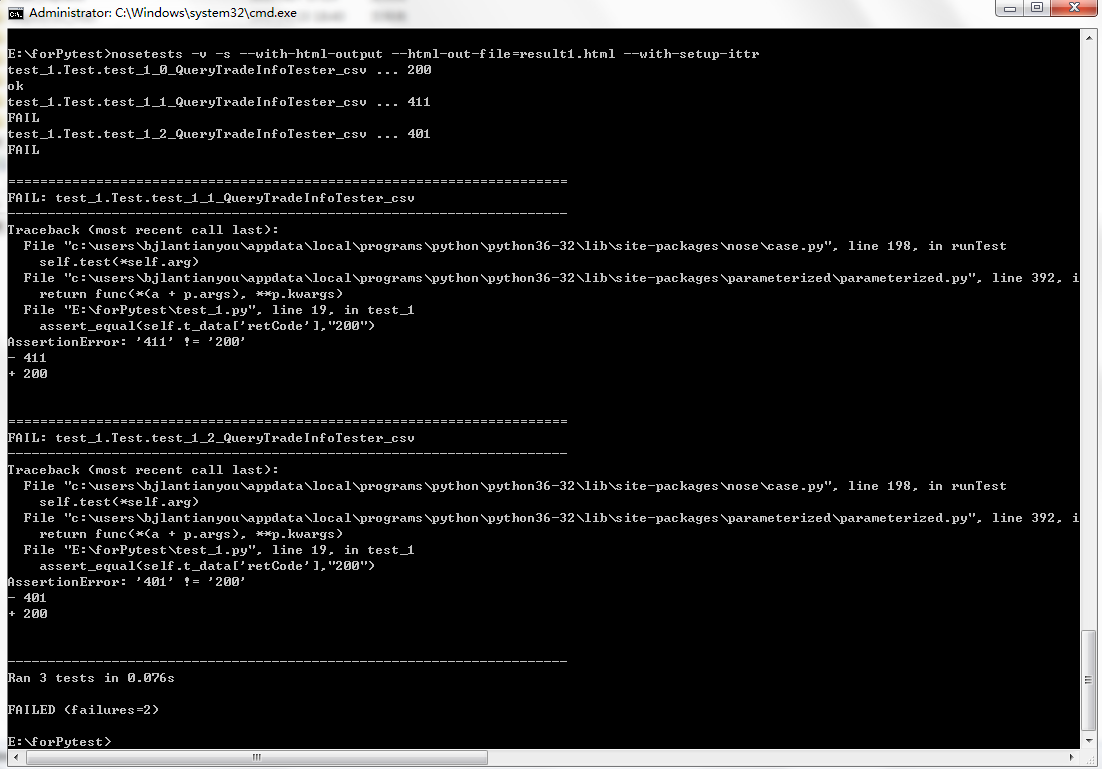
现在在待测目录下执行nosetests命令就不会报错了,通过执行以下命令可以在测试结束后自动生成测试结果报告的html文件,还可以显示print内容进行程序调试:
nosetests -v -s --with-html-output --html-out-file=result1.html --with-setup-ittr
运行效果如下:
生成的报表文件如下:
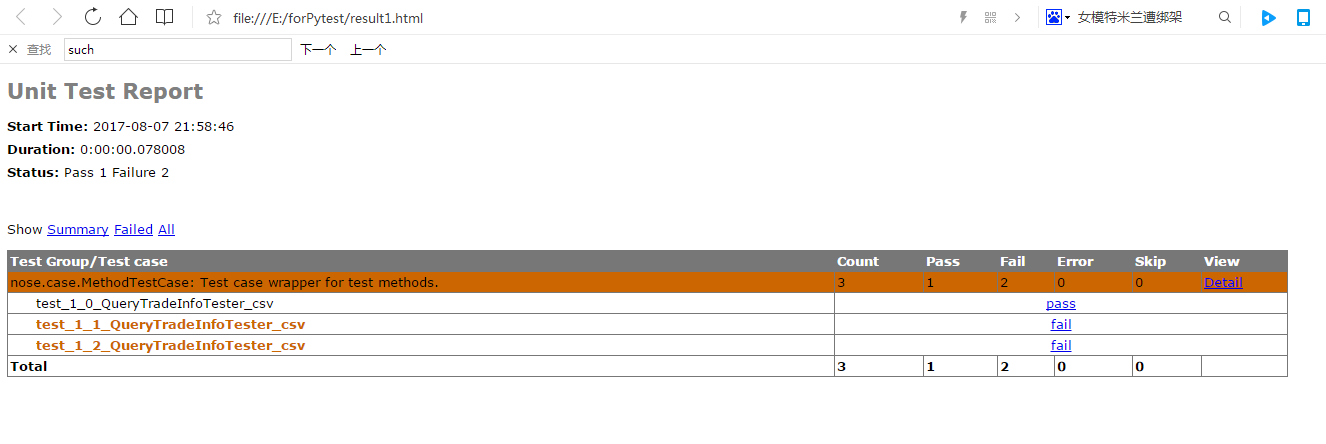
至此nose就完成了到python3的过度,我避开了使用nose_ittr,而是借鉴nose_ittr插件的做法自己写了一个专门用来取测试数据的工具类,配合nose_parameterized一起发挥数据驱动的作用。通过命令行就可以执行nose测试,所以也会很方便与jenkins进行整合构建以达到持续集成的目的。
转载地址:http://ltuta.baihongyu.com/